Unvergleichliche End-to-End-Plattform für beschleunigtes Computing
Die NVIDIA HGX Plattform bündelt die Leistungsfähigkeit von NVIDIA GPUs, NVIDIA NVLink, NVIDIA Networking und optimierten Software-Stacks für KI und High-Performance-Computing. Dadurch lassen sich moderne Rechenzentrumsumgebungen auf maximale Anwendungsleistung und eine schnellere Time-to-Insight ausrichten.
Die NVIDIA HGX B300 integriert acht NVIDIA Blackwell Ultra GPUs mit Hochgeschwindigkeits-Interconnects und positioniert sich als leistungsstarke Scale-Up-Plattform für generative KI, anspruchsvolle Datenanalyse und HPC. Im Vergleich zur HGX B200 nennt NVIDIA unter anderem 1,5-fach mehr FP4 Tensor Core FLOPS im dichten Format, doppelte Attention-Performance sowie mehr Netzwerkbandbreite innerhalb der Plattform.
KI-Leistung und Vielseitigkeit
Die HGX B300 adressiert Workloads, bei denen hoher Durchsatz, schnelle Reaktionszeiten und effiziente Kommunikation zwischen GPUs entscheidend sind. Damit eignet sie sich für Inferenz großer Modelle, Training im großen Maßstab und datenintensive Rechenaufgaben in produktiven KI-Umgebungen.
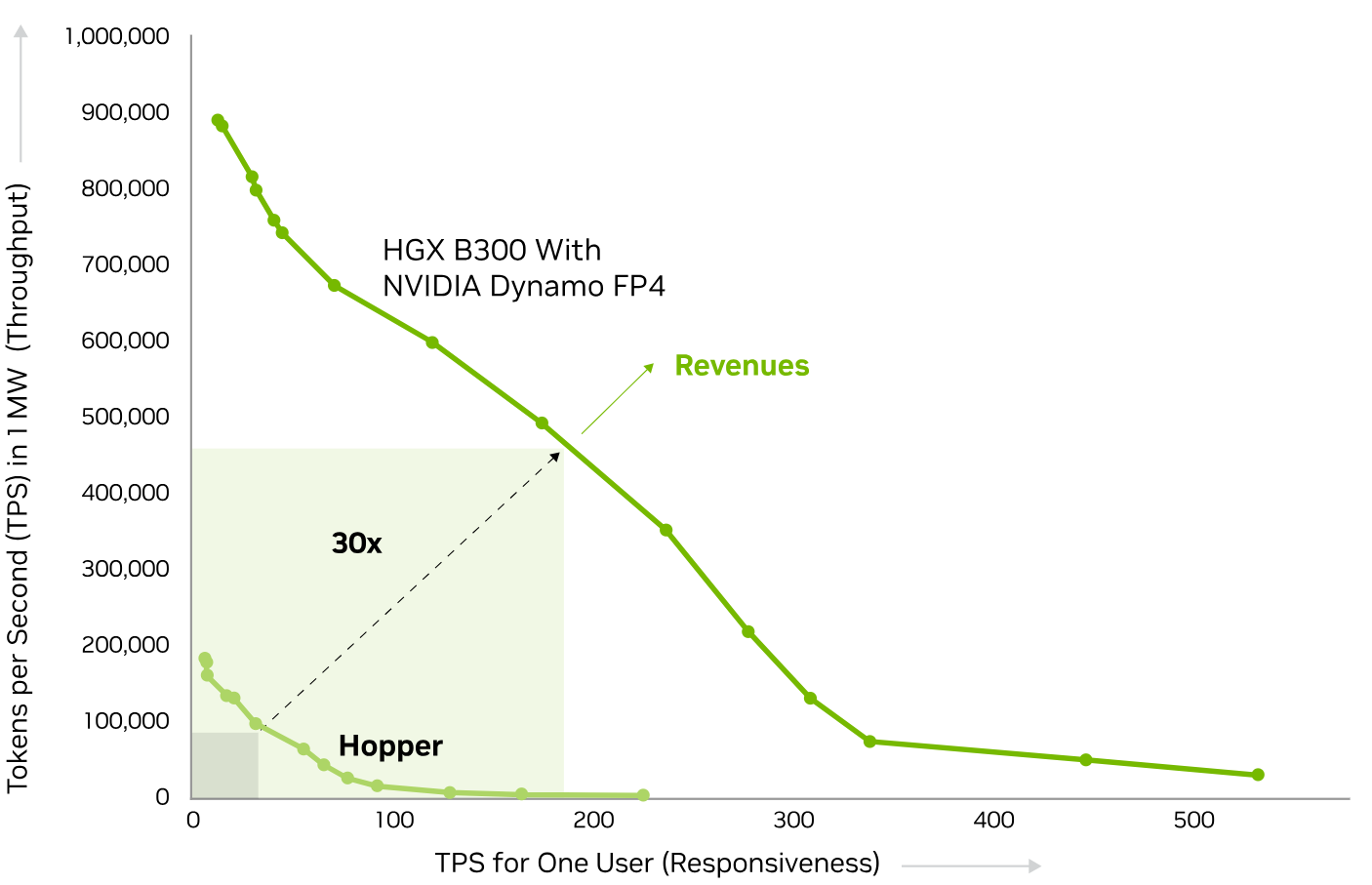
Mehr Output für AI Factories
Die sogenannte Frontier-Kurve stellt den Zusammenhang zwischen GPU-Durchsatz in Tokens pro Sekunde und der Interaktivität für einzelne Nutzer dar. Laut NVIDIA kann die HGX B300 am optimalen Schnittpunkt von Durchsatz und Reaktionszeit eine deutlich höhere AI-Factory-Leistung erreichen. In der gezeigten Darstellung wird eine bis zu 30-fache Steigerung gegenüber der NVIDIA Hopper Architektur hervorgehoben.
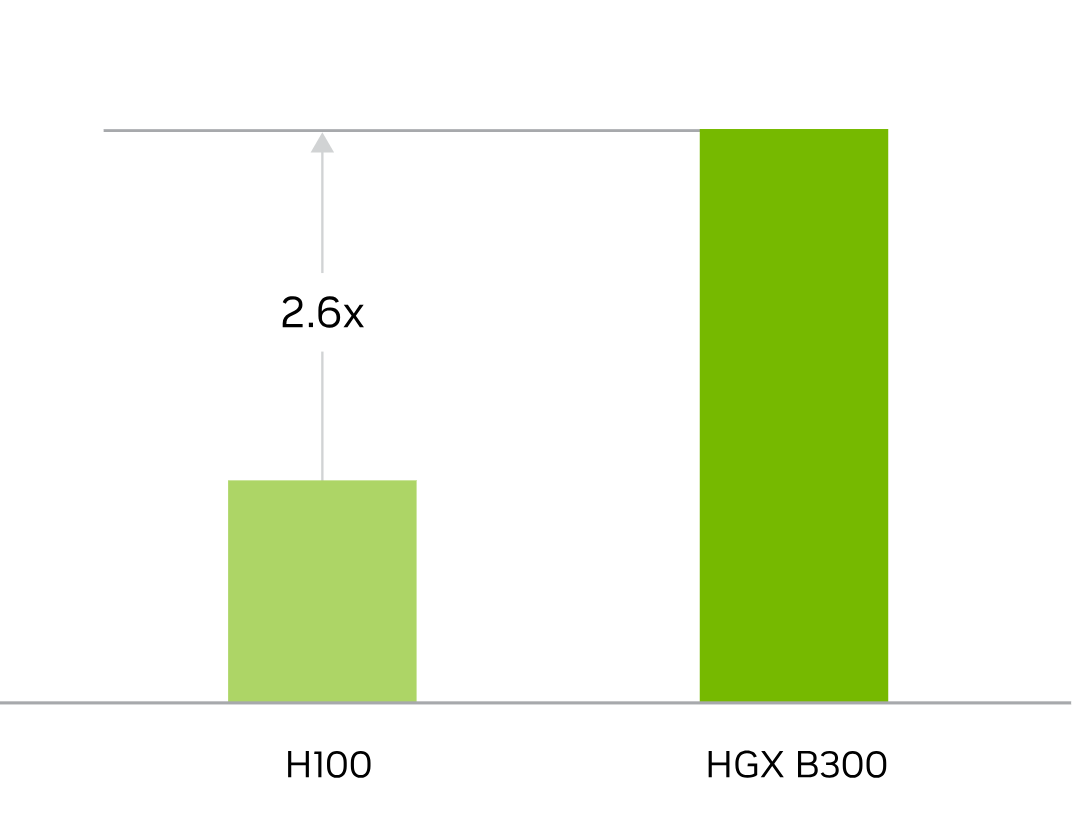
Skalierbares Training für große KI-Modelle
Für das Training großer Sprachmodelle hebt NVIDIA eine bis zu 2,6-fach höhere Trainingsleistung für Szenarien wie DeepSeek-R1 hervor. Die Plattform verfügt über mehr als 2 TB Hochgeschwindigkeitsspeicher und 14,4 TB/s NVLink Switch Bandbreite, um die Kommunikation zwischen den GPUs effizient zu halten und das Training im großen Maßstab zu unterstützen.
Beschleunigung durch NVIDIA Networking
In KI- und HPC-Clustern ist das Netzwerk ein zentraler Leistungsfaktor. Für scale-out-orientierte Umgebungen unterstützt NVIDIA HGX moderne Netzwerkarchitekturen mit NVIDIA Quantum InfiniBand und NVIDIA Spectrum-X. Beide Ansätze zielen auf geringe Latenz, hohe Bandbreite und eine bessere Auslastung verteilter Rechenressourcen.
Für KI-Cloud-Rechenzentren mit Ethernet-Infrastruktur positioniert NVIDIA Spectrum-X als Plattform für hohe KI-Leistung über Ethernet. In Verbindung mit passenden Switches und NICs unterstützt sie Performance-Isolation, vorhersehbare Ergebnisse bei parallelen KI-Jobs, Multi-Tenancy und Zero-Trust-orientierte Sicherheitskonzepte.
Typische Einsatzbereiche
- Generative KI und große Sprachmodelle
- AI Factories und skalierte Inferenz-Umgebungen
- Training großer Modelle und multimodaler Systeme
- High-Performance-Computing und Simulation
- Datenanalyse und GPU-beschleunigte Rechenzentren